The following is the text that accompanied the M-AILABS Speech DataSet:
The M-AILABS Speech Dataset is the first large dataset that we are providing free-of-charge, freely usable as training data for speech recognition and speech synthesis.
Most of the data is based on LibriVox and Project Gutenberg. The training data consist of nearly thousand hours of audio and the text-files in prepared format.
A transcription is provided for each clip. Clips vary in length from 1 to 20 seconds and have a total length of approximately shown in the list (and in the respective info.txt-files) below.
The texts were published between 1884 and 1964, and are in the public domain. The audio was recorded by the LibriVox project and is also in the public domain – except for Ukrainian.
Ukrainian audio was kindly provided either by Nash Format or Gwara Media for machine learning purposes only (please check the data info.txt files for details).
Before downloading, please read the license agreement at the bottom of this posting first!
Intro
People have asked us “Why”, i.e. “why are you giving away this much highly valuable data”.
The quick answer is: because our mission is to enable (European) companies to take advantage of AI & ML without having to give up control or know-how.
The full answer would be significantly longer, but let’s say we just want to advance the use of AI & ML in Europe.
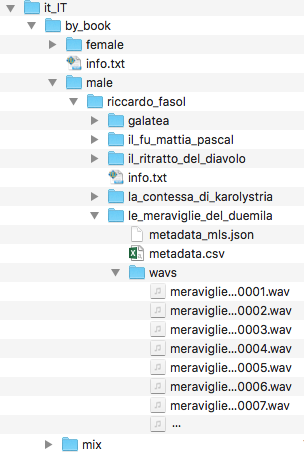
Directory Structure
Each language is represented by its international ISO-Code for language + country (e.g. de_DE for de=German, DE=Germany) plus an addition by_book directory.
Below that, you will find directories named:
- female
- male
- mixed
The training data is split into female, male and mixed voices. In case of mixed, the training data contains male and female data mixed.
For each voice, there is the name and some info.txt containing information about the training data. Each training-data directory contains two files:
metadata.csvmetadata_mls.json
The full directory structure looks like this:
Format
All audio-files are in wav-format, mono and 16000 Hz.
The complete training data is in the MLS (M-AILABS)- and LJSpeech-Format. Each book contains its own metadata.csv and metadata_mls.json.
Those of you who know the LJSpeech data format will immediately recognize the .csv-file. The _mls.json file contains the same information as the .csv-file except that that information is in JSON-format.
Each line in a metadata.csv consist of a filename (without extension) and two texts, separated by a “|“-symbol. The text includes upper- and lower-case characters, special-characters (such as punctuation) and more. If you need clean-text, please clean it before using it. For Speech Synthesis, sometimes you need all special characters.
The first text contains the fully original data, including non-normalized numbers, etc. The second version of the text contains the normalized version, meaning numbers have been converted to words and some cleanup of “foreign” characters (transliterations) have been applied.
Both files are in UTF-8-Format. Do not try reading it in ASCII, it won’t work.
grune_haus_01_f000002|Ja, es ist ein grünes Haus, in dem ich 1989 wohne...|... eintausendneunhundert... grune_haus_01_f000003|Es ist nicht etwa grün angestrichen wie ein Gartenzaun... grune_haus_01_f000004|die Menschen verstehen noch immer nicht die Farben so... grune_haus_01_f000005|Dann wachsen die Haselsträucher und die Kletterrosen so... grune_haus_01_f000006|und wenn der Wind kommt, weht er Laub und Blütenblätter... grune_haus_01_f000007|In diesem grünen Hause wohne ich mit meinen drei Kindern... grune_haus_01_f000008|die noch nicht in die Schule geht und ein großer Wildfang... grune_haus_01_f000009|Denkt nur, neulich wollte sie durchaus die Blumen von meinem... ...
The .wav-files can be found in the directory wavsin the same directory as where the metadata.csvresides.
Note: each .wav-file has 0.5 seconds of silence at the beginning and at the end of it. If you don’t need it, you can just remove it using soxor ffmpeg.
Usage
If you have any training model that supports LJSpeech data format for preprocessing, you can just run that preprocessing tool on metadata.csv and life will be fine. Otherwise, you will need to do your own preprocessing.
In the original format that we provide, the files are separated as shown in the directory structure above.
But, since all .wav-files within a given language have guaranteed unique names, you can copy them all into a single wavs-directory and generate the metadata.csv for that by using the following shell-command (Linux + macOS):
cat <metadata.csv_1> <metadata.csv_2> ... >> new_metadata.csv
Some Hints on Using the Data
It is important to know that languages evolve over time and introduce words from other languages. For example, the word ‘Exposé’ exists in the German language and was ‘imported’ from French. But the character ‘é’ is not a base character of the German alphabet. It exists only for special purposes like the one shown here.
You have two options (the second being the better option):
- Leave it as is and add the character ‘é’ to your German character-set
- Replace it by ‘e’, which is done in the transliterated version of the text (second column)
In the first case, this can result in “not-so-good” learning as that character doesn’t show up too often and your DNN might not learn well. Then again, you may want to separate between ‘e’ and ‘é’.
In the second case, this word will be learned the same as ‘Expose’, which may not be what you want.
This is valid for all texts, including in other languages. We decided, after some discussion, to not remove data but instead leave it up to you to decide which information to use and which not to use. Thus, we are providing you both version of the text: a version including those characters and a version where those characters are transliterated (e.g., the Turkish “ç”, if it shows up in German text, is transliterated to “tsch”).
For speech recognition, we usually generate multiple version of the same data in a flat-directory structure. Each additional version has noise added to it such as Cafe-backgrounds, City, Crowded Markets, Data Centers, Mega-City-Noise, Train, People Talking and more. If we add all our noise to, e.g., German, we generate usually around 2,800 hours of training data out of the existing, clean 237hrs. We recommend you experiment with similar approaches.
Since the data is used for Speech Recognition (STT) as well as Speech Synthesis, we are providing clean-audio versions here.
Warning: in some very, very rare cases, there may be a wav-file missing though the filename shows up in the metadata.csv file. In these cases, you can just ignore the entry. We have found about six(!) cases where this happens (en_UK:2, en_US:3, es_ES:1). Bear with us, there were hundreds of thousands of files to handle…
Character Sets
Following character sets have been used in the data in the transliterated, cleaned version:
ASCII: 'ABCDEFGHIJKLMNOPQRSTUVWYXZabcdefghijklmnopqrstuvwxyz0123456789!\',-.:;? '
English: ASCII
German: ASCII + 'äöüßÄÖÜ'
Italian: ASCII + 'àéèìíîòóùúÀÉÈÌÍÎÒÓÙÚ'
Spanish: ASCII + '¡¿ñáéíóúÁÉÍÓÚÑ'
French: ASCII + 'àâæçéèêëîïôœùûüÿŸÜÛÙŒÔÏÎËÊÈÉÇÆÂÀ'
Ukrainian: ASCII +
 Russian: ASCII +
Russian: ASCII +
 Polish: ASCII +
Polish: ASCII +

Statistics & Download Links
| Language | Country | Tag | Length | Size | DL Size | Sample | DL Link |
|---|---|---|---|---|---|---|---|
| German | Germany | de_DE | 237h 22m | 27 GiB | 20 GiB | F / M | DOWNLOAD |
| English | Queen’s | en_UK | 45h 34m | 4.9 GiB | 3.5 GiB | F / M | DOWNLOAD |
| English | US | en_US | 102h 07m | 11 GiB | 7.5 GiB | F / M | DOWNLOAD |
| Spanish* | Spain | es_ES | 108h 34m | 12 GiB | 8.3 GiB | F / M | DOWNLOAD |
| Italian | Italy | it_IT | 127h 40m | 14 GiB | 9.5 GiB | F / M | DOWNLOAD |
| Ukrainian | Ukraine | uk_UK | 87h 08m | 9.3 GiB | 6.7 GiB | F / M | DOWNLOAD |
| Russian | Russia | ru_RU | 46h 47m | 5.1 GiB | 3.6 GiB | F / M | DOWNLOAD |
| French v0.9** | France | fr_FR | 190h 30m | 21 GiB | 15 GiB | F / M | DOWNLOAD |
| Polish* | Poland | pl_PL | 53h 50m | 5.8 GiB | 4.2 GiB | F / M | DOWNLOAD |
| TOTALS (downloadable) | 999h 32m | ~110 GiB | ~78 GiB |
*: I was made aware that the speaker “karen” is Mexican and the speaker “victor” is Argentinian. On one hand, I apologize for the mishap. On the other, this adds a few hours of Latin American Spanish to the collection. Please be aware of this difference.
** : French is v0.9, i.e., without transliteration and normalization of numbers.
License
Copyright (c) 2017-2019 by the original creators @ M-AILABS with the following license:
Redistribution and use in any form, including any commercial use, with or without modification are permitted provided that the following conditions are met:
- Redistributions of source data must retain the above copyright notice, this list of conditions and the following disclaimer.
- Neither the name of the copyright holder nor the names of its contributors may be used to endorse or promote products derived from this downloaded data, source-code or binary-code without specific prior written permission.
THIS DATA IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS “AS IS” AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE and/or DATA, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
Closing Words
We hope that you will create the most interesting, fascinating and rich speech recognition and speech synthesis solutions. Please do contact us if you have developed and/or marketed something based on this data. We would be happy to hear it.
If you have any questions, please feel free to contact me.
As of October 2018, this data is provided courtesy of Imdat Solak.
Any license restrictions you may find in downloaded data is removed herewith, only valid license (which is even more free than before) is shown above.